MLODE 2014, September 1-2 in Leipzig, Germany
Content analysis and the Semantic Web, a LIDER Hackathon
T9: Converting the output of Babelfy into RDF-NIF
SUMMARY
Topic description
Babelfy is a unified, multilingual, graph-based approach to Entity Linking and Word Sense Disambiguation.
Based on a loose identification of candidate meanings, coupled with a densest subgraph heuristic which selects high-coherence semantic interpretations,
Babelfy is able to annotate free text with with both concepts and named entities drawn from BabelNet’s sense inventory.
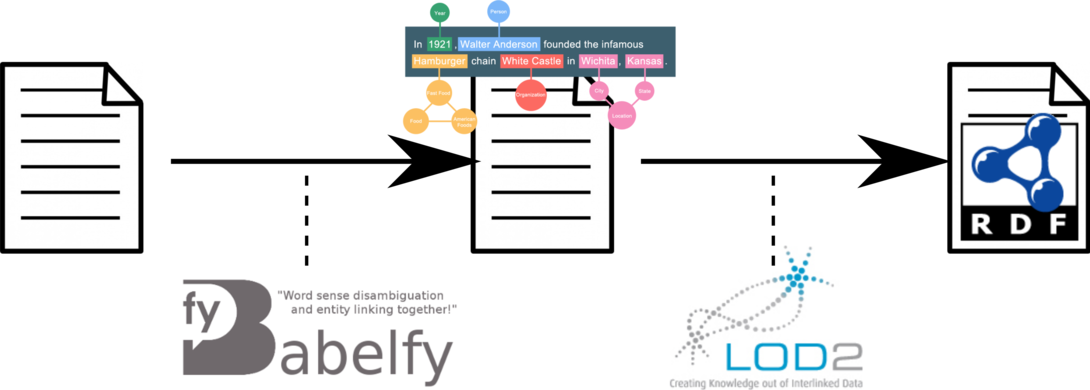
The task consists of converting text annotated by Babelfy into RDF format.
In order to accomplish this, participants will start from free text, will annotate it with Babelfy and make use of the NLP2RDF NIF module.
Objective
INPUT: free text, in any of the 50 languages available in BabelNet.
INTERMEDIATE OUTPUT: enriched text, semantically annotated via Babelfy.
OUTPUT: semantically annotated text converted into NIF-RDF format.
The following figure shows the workflow of the task.
 |
Note: We released a demo package that shows you how the input and the output should look like (see details below, section Instructions).
The objective of this hackathon is to try to mime the behaviour of the demo yourself.
|
Requirements
- Basic Java programming skills
- Basic RDF knowledge
Software requirements
- A text editor (but an IDE is recommended: Eclipse, Netbeans, etc.)
- Java 1.6 or greater
Data requirements
Instructions
- Download BabelNet stanford indexes from http://babelnet.org/download (direct link: http://babelnet.org/data/2.5/babelnet-2.5-index-bundle.tar.bz2)
- Unpack it with
bzip2 -d babelnet-2.5-index-bundle.tar.bz2
tar xvf babelnet-2.5-index-bundle.tar
You should now have a directory called 'BabelNet-2.5'
- Download the hackathon demo here
-
Uncompress the hackathon demo file to your project directory
tar xzvf YOUR_PROJECT_DIR leipzig_hackathon_t9_babelfy2nif.tar.gz
You should now have the following structure:
.
├── config/
├── lib/
├── models/
├── resources/
├── leipzig_hackathon-0.0.1-SNAPSHOT-jar-with-dependencies.jar
└── run_babelfy2nif-demo.sh
- Open config/babelnet.var.properties and set the variable babelnet.dir to the directory containing BabelNet's indexes. For example, if you have the indexes under the directory /home/flati/resources/BabelNet-2.5, set
babelnet.dir=/home/flati/resources/BabelNet-2.5
- Run the demo
sh run_babelfy2nif-demo.sh
-
Take a look at the file config/babelfy2nif.properties. It has several parameters that allows the customization of the demo.
- The Babelfy key: you will be given one during the hackathon. The key allows you to freely query Babelfy and obtain disambiguated text.
- Language: the language you want to work with. This can be any of the 50 languages offered by BabelNet.
- Text: the text you want to annotate and convert into NIF.
- Algorithm: the way Babelfy's overlapping annotations are handled (you can select either FIRST_COME_FIRST_SERVED_ALGORITHM or LONGEST_ANNOTATION_GREEDY_ALGORITHM).
- RDF format: the format of your NIF output. This is quite standard and you can choose among TURTLE, RDF/XML and NTRIPLE representations.
- Output: where you want the result to be displayed. This can either be the standard output (stdout) or your favourite file (file).
- Output file: if the output was set to file, this parameter determines the file path in which the output will be written.
Useful links
- Babelfy tutorial [see]
- NIF explanation [see]
- Brown 2 NIF tutorial [see] and an example of how a corpus converted into NIF looks like [see]
An example
The demo feeds Babelfy with the following sentence
Hello World!
and then converts it into NIF.
The result of this is contained into a newly-created file called rdf_output.nif.txt which looks like the following: